Abstract
We present Analogical Networks, a model that casts fine-grained 3D visual parsing as analogy-forming inference: instead of mapping input scenes to part labels, which is hard to adapt in a few-shot manner to novel inputs, our model retrieves related scenes from memory and their corresponding part structures, and predicts analogous part structures in the input object 3D point cloud, via an end-to-end learnable modulation mechanism. By conditioning on more than one retrieved memories, compositions of structures are predicted, that mix and match parts across the retrieved memories. One-shot, few-shot or many-shot learning are treated uniformly in Analogical Networks, by conditioning on the appropriate set of memories, whether taken from a single, few or many memory exemplars, and inferring analogous parses. We show Analogical Networks are competitive in many-shot settings and outperform existing state-of-the-art detection transformer models on part segmentation in few-shot scenarios, as well as paradigms of meta-learning and few-shot learning. Our model successfully parses instances of novel object categories simply by expanding its memory, without any weight updates.
Analogical Networks Architecture
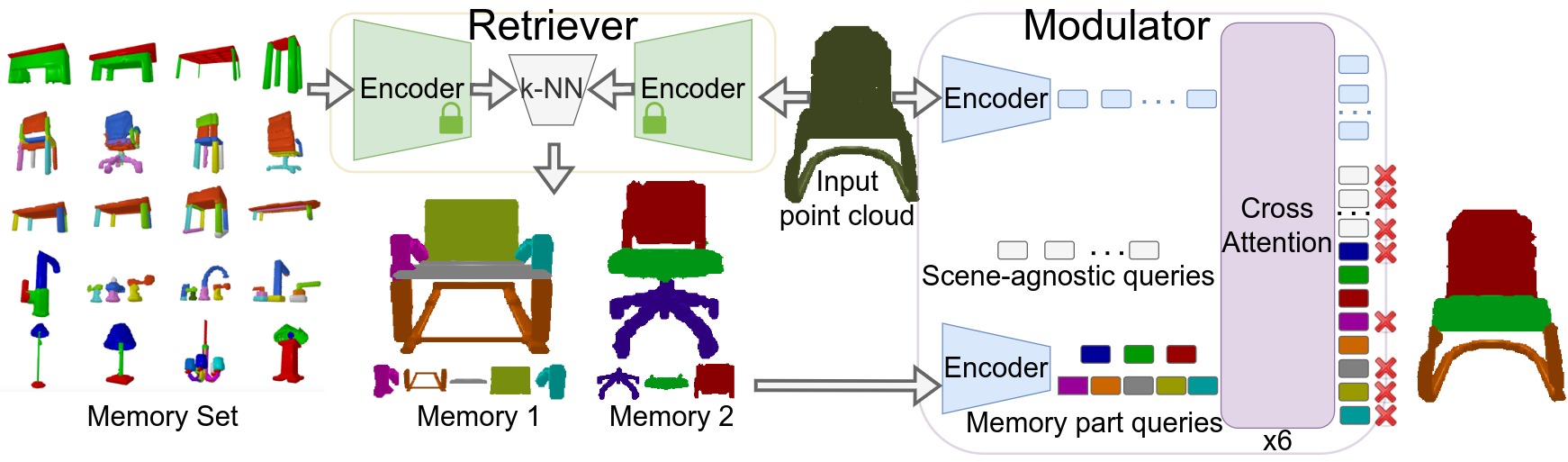
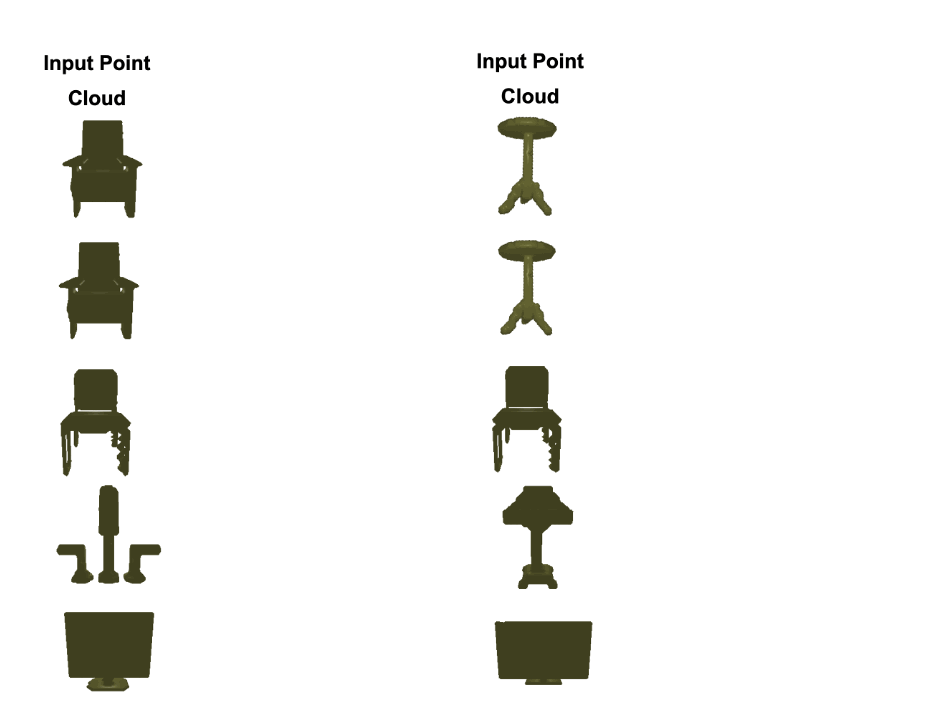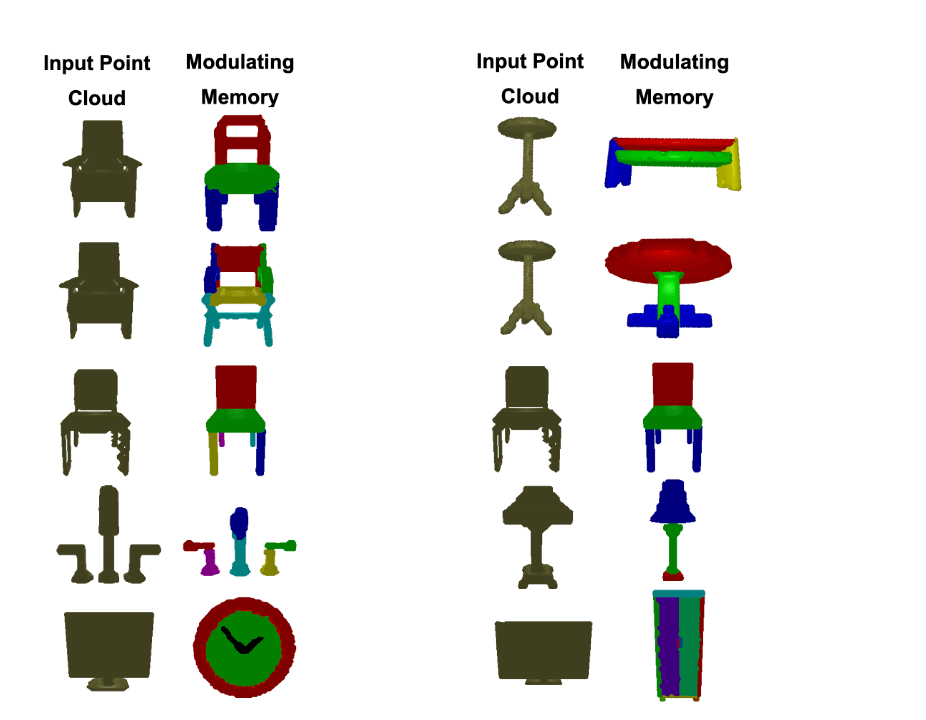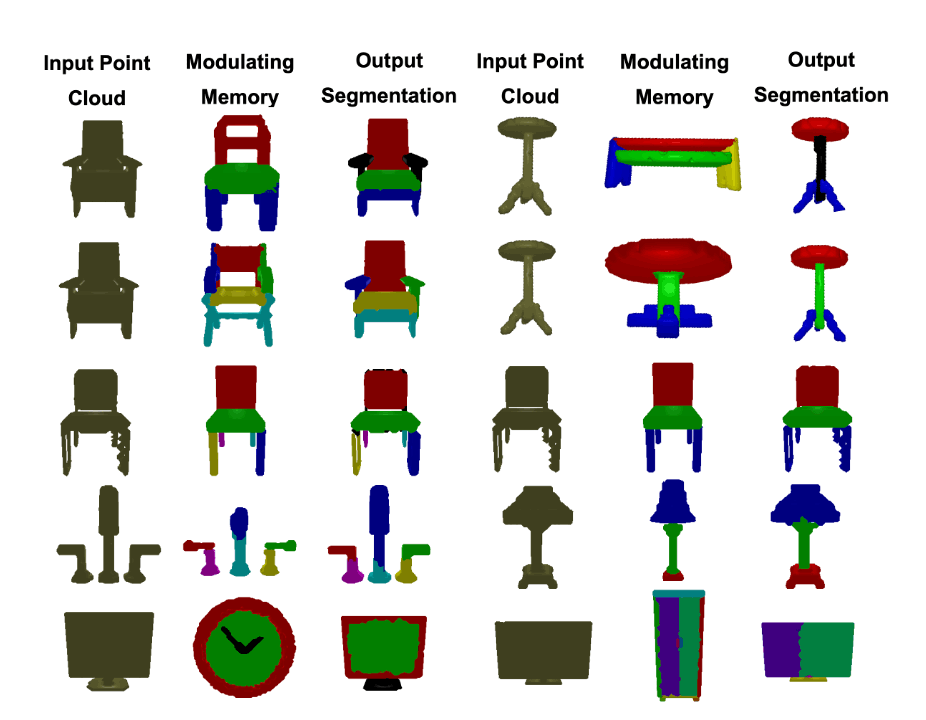
Analogical Networks are comprised of retriever and modulator sub-networks. In the retriever, labelled memories and the (unlabelled) input point cloud are separately encoded into feature embeddings and the top-k most similar memories to the present input are retrieved. In the modulator, each retrieved memory is encoded into a set of part feature embeddings and initializes a query that is akin to a slot to be “filled” with the analogous part entity in the present scene. These queries are appended to a set of learnable parametric scene-agnostic queries. The modulator contextualizes the queries with the input point cloud through iterative self and cross-attention operations that also update the point features of the input. When a memory part query decodes a part in the input point cloud, we say the two parts are put into correspondence by the model. We color them with the same color to visually indicate this correspondence